Ziv Bar-Yossef1 |
Sridhar Rajagopalan | |
|
University of California at Berkeley 387 Soda Hall Berkeley, CA 94720-1776, USA zivi@cs.berkeley.edu |
San Jose, CA 95120, USA sridhar@almaden.ibm.com |
Copyright is held by the author/owner(s).
WWW2002,
May 7-11, 2002, Honolulu, Hawaii, USA.
ACM 1-58113-449-5/02/0005.
We formulate and propose the template detection problem, and suggest a practical solution for it based on counting frequent item sets. We show that the use of templates is pervasive on the web. We describe three principles, which characterize the assumptions made by hypertext information retrieval (IR) and data mining (DM) systems, and show that templates are a major source of violation of these principles. As a consequence, basic ``pure'' implementations of simple search algorithms coupled with template detection and elimination show surprising increases in precision at all levels of recall.
Categories and Subject Descriptors: H.3.3 [Information
Systems]: Information Search and Retrieval
General Terms:
Algorithms
Keywords: Information Retrieval, Hypertext, Web
Searching, Data Mining
This paper deals with a novel application of the classical (see Agrawal and Srikant [1]) frequent item set based data mining paradigm to the area of search and mining of web data. We also address an interesting software architecture issue, namely, what should be the boundary between crawling (or data gathering) systems and ranking, mining or indexing (generically, data analysis) systems. We take the point of view that the latter data analysis tools should be both clean in concept and simple in implementation, and should not, in particular, include logic for dealing with many special cases. It should be the responsibility of the data gathering system to provide clean data. This boundary is important—the effort involved in cleaning the raw data can be effectively leveraged by a large number of data analysis tools.
In the following pages, we describe a set of three well understood principles, the Hypertext IR Principles, which may be thought of as the basic tenets of a contract between gathering subsystems and analytic ones. We justify these principles based on three case studies drawn from the web search and mining literature. We then apply these principles to define the template detection problem and show that it is an instance of the frequent item set counting problem which is well studied in the classical data mining world. However, the size and scale of the problem preclude the use of existing algorithmic methods (such as a priori or the elimination generation method) and necessitates the invention of new ones. We discuss one solution which is very effective in practice. We show that applying our method results in significant improvements in precision across a wide range of recall values. We feel that similar improvements should follow for most if not all other hypertext based search and mining algorithms.
The context: What is the appropriate interface between data gathering and data processing in the context of web search and mining systems? (a) Modern hidden web and focused crawlers, as well as (b) Requirements imposed by the robots.txt robots exclusion and politeness protocols have meant the incorporation of sophisticated queuing and URL discovery methods into the crawler. Increasingly, data cleaning tasks such as mirror and duplicate detection have been transferred to gathering subsystems.
The new shift marks a change in the software engineering of web search and mining systems wherein increasingly ``global'' analysis is being expected of gathering subsystems. On one hand, this increases the complexity of crawling systems. On the other, it raises the possibility of multiple data mining algorithms reaping the benefits of a common data cleaning step. We will discuss this issue further in Section 1.1.
Templates and data mining: In this paper, we will focus on a particularly interesting and recently emerging issue which impacts a number of algorithmic methods. Many websites, especially those which are professionally designed, consist of templatized pages. A templatized page is one among a number of pages sharing a common administrative authority and a look and feel. The shared look and feel is very valuable from a user's point of view since it provides context for browsing. However, templatized pages skew ranking, IR and DM algorithms and consequently, reduce precision.
In almost all instances, pages sharing a template also share a large number of common links. This is not surprising since one of the main functions of a template is in aiding navigation. If we consider web pages as items, and the set of web pages cited on any particular web page as an item set, then a frequent item set corresponds to a template. Thus, finding templates can be viewed as an instance of the frequent itemset counting paradigm. The size of the web, however, precludes using a priori [1] to identify template instances. Alternative methods such as the elimination generation method [20] also fail.
The basic principles: Despite their differences in detail, there are three important principles (or assumptions)—which we call the Hypertext IR Principles henceforth—underlying most, if not all, reference based (or hypertext) methods in information retrieval. We do not intend that these are exclusive, but that these cover almost all the algorithmic uses that links have been put to.
The creation of a link on the WWW represents the following type of judgment: the creator of page p by linking to page q has to some measure conferred authority on q.Brin and Page [3,23] in defining the PageRank ranking metric say that links express a similar motive:
The intuition behind PageRank is that it uses information external to the pages themselves - their backlinks, which provides a kind of peer review.
It affords an immediate step, however, to associative indexing, the basic idea of which is a provision whereby any item may be caused at will to select immediately and automatically another. This is the essential feature of the memex. The process of tying two items together is the important thing.An extension of the Lexical Affinity Principle is detailed in Chakrabarti's work [6]. In this work, he proposes that distance between entities within a document should be measured by considering document structure and not simply some linearization of it. For instance, the distances between all pairs of elements within an itemized list should be uniform.
Our contributions: In this paper, we take the point of view that the Hypertext IR Principles form a sound basis for defining the contract between modern data gathering and data analysis systems. Thus, the function of a good data gathering system should be to preprocess the document corpus so that violations of the Hypertext IR Principles are minimized. This has two benefits. First, it results in better software design, with a potentially large number of different analysis and mining algorithms leveraging the effort expended in the pre-processing phase. Second, the data analysis algorithms can be retained in ``pure form'' and would not need to expend a lot of effort dealing with special cases.
We illustrate this principle by considering the problem caused by templatized pages. Our discussion in this context is three fold. First, we define templates and argue that templates are a source of wholesale violation of the Hypertext IR Principles. We then formulate and describe data mining algorithms to detect and flag templates. We then show that applying a ``pure form'' ranking algorithm (Clever, with no bells and whistles) to the template eliminated database results in remarkable improvements in precision at all recall levels across the board. We finally speculate that the same approach will work in a more general context.
The web contains frequent violations of the Hypertext IR Principles. These violations are not simply random. They happen in a systematic fashion for many reasons, some of which we describe below.
Systematic violations of the Hypertext IR Principles result in a host of well known problems. Most search and mining engines have a lot of special purpose code to deal with each such problem. We describe some prominent classes of these problems here.
Modern web pages (see, for instance, Figure 1), contain many elements for navigational and other auxiliary purposes. For example:
This implies that much of the noise problem follows from violations of the Relevant Linkage Principle and the Topical Unity Principle that are caused by the construction of modern web pages.
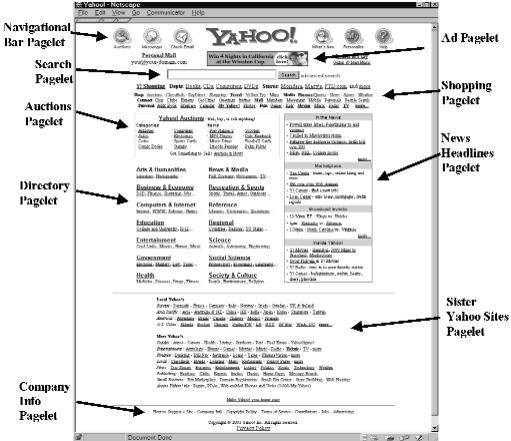
A pagelet (cf., [6,11]) is a self-contained logical region within a page that has a well defined topic or functionality. A page can be decomposed into one or more pagelets, corresponding to the different topics and functionalities that appear in the page. For example, the Yahoo! homepage, www.yahoo.com (see Figure 1), can be partitioned into the main directory pagelet at the center of the page, the search window pagelet above it, the navigational bar pagelet at the top, the news headlines pagelet on the side, and so forth.
We propose that pagelets, as opposed to pages, are the more appropriate unit for information retrieval. The main reason is that they are more structurally cohesive, and better aligned with both the Topical Unity Principle and the Relevant Linkage Principle. Several issues concerning the process of discovery and use of pagelets are discussed in Section 3.1.
A frequent and systematic violation of the Hypertext IR Principles is due to the proliferation in the use of templates. A template is a pre-prepared master HTML shell page that is used as a basis for composing new web pages. The content of the new pages is plugged into the template shell, resulting in a collection of pages that share a common look and feel.
Templates can appear in primitive form, such as the default HTML code generated by HTML editors like Netscape Composer or FrontPage Express, or can be more elaborate in the case of large web sites. These templates sometimes contain extensive navigational bars that link to the central pages of the web site, advertisement banners, links to the FAQ and Help pages, and links to the web site's administrator page. See Figure 2 for a representative example: the Yahoo! template.
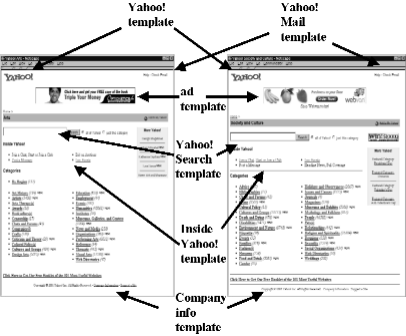
The use of templates has grown with the recent developments in web site engineering. Many large web sites today are maintained automatically by programs, which generate pages using a small set of formats, based on fixed templates. Templates can spread over several sister web sites (e.g., a template common to amazon.com and drugstore.com), and contain links to other web sites, such as endorsement links to business partner web sites (www.eunet.net), advertisement links, and ``download'' links. Thus, traditional techniques to combat templates, like intra-site link filtering, are not effective for dealing with their new sophisticated form.
Since all pages that conform to a common template share many links, it is clear that these links cannot be relevant to the specific content on these pages. Thus templates violate both the Relevant Linkage Principle and the Topical Unity Principle. They may (and do) also cause violations of the Lexical Affinity Principle, if they are interleaved with the actual content of the pages. Therefore, improving hypertext data quality by recognizing and dealing with templates seems essential to the success of the hypertext IR tools.
A template has two characterizing properties:
The latter property is important in order to distinguish between templates, in which a collection of pages intentionally share common parts, and the following:
Note that the requirement that a central authority influences all pages that conform to a template does not necessarily imply that they all belong to a single web site. The central authority can also be one that coordinates templates between sister sites.
In Section 3.2 we give a formal definition of templates, and show two efficient algorithms to detect templates in a given dataset of pages. Having the ability to detect templates, we can discard them from the dataset, and thus improve its quality significantly. Our thesis is that pagelet-based information retrieval has to go hand in hand with template removal, in order to achieve the desired improvement in performance. In the applications we consider in Section 4 we pursue this direction, and show in Section 5 that this results in better performance for pagelet-based Clever.
In this section, we pick three modern canonical algorithms using link based analysis and, in each case, describe their reliance on the Hypertext IR Principles described earlier.
HITS [19] is a ranking algorithm for hypertext corpora. The goal is
to choose, given a query t, from a base set of pages, G(t),
all of which are assumed to be relevant to t, the most relevant pages.
This is done as follows. Start from an initial assignment h(p) = a(p) =
1 for each page p in G(t) and iteratively perform the
following update steps:
|
Here, I(p) and O(p) denote the pages which point to and are pointed to respectively by p. When normalized after each update, h(p) and a(p) converge to a fixed point, known as the hub and authority score respectively. The higher these scores, the more relevant the pages to the query term t.
Discussion The methods (2) suggested in [21] and (3) suggested in [2,7] require significant query time processing, which per se, would not be required if the data were preprocessed to satisfy the Topical Unity Principle and the Lexical Affinity Principle respectively. Moreover, if a more sophisticated method, such as that suggested by Davison [14] were used to clean the data beforehand, the (somewhat unsatisfactory) hack (1) used in [19] would not be required either.
A focused crawler is a program that looks for pages that are relevant to some node in a given taxonomy. The notion of focused crawling was introduced and first discussed in [12,13]. The solution proposed (called FOCUS) consisted of three components: a crawler, a classifier, and a distiller. The three components work in concert as follows: The function of the crawler was to fetch pages from the web according to a given priority. The classifier locates these fetched pages within the taxonomy, and the distiller tags pages in each taxonomy node with a relevance score, which is then used to prioritize those unfetched pages that are pointed to by highly relevant nodes for fetching by the crawler.
The distiller used by FOCUS was Clever, which is a variant of Kleinberg's HITS Algorithm. The classifier used was HyperClass, described in [9].
Discussion The measure of effectiveness of a focused crawler is (1) its harvest rate—the fraction of pages that are downloaded by it which are relevant to some node in the taxonomy and (2) the accuracy with which these pages are located within the taxonomy. Following (1), a good distiller would result in better prioritization of the pages to be fetched, and thus directly improve harvest rate. Moreover, if the data would adhere more closely to the Relevant Linkage Principle and the Topical Unity Principle following (2), pointers to irrelevant material would not be followed, and would directly improve harvest rate. Finally, any improvements to HyperClass (3) accruing from cleaner data would automatically improve the accuracy of the focused crawler.
The co-citation algorithm is a simple algorithm due to Dean and Henzinger [15]. Given a page p, the algorithm finds all pages which are ``similar'' in content by looking for other pages that are most often co-cited with p.
At its heart the co-citation algorithm is an immediate consequence of assuming the Topical Unity Principle and the Relevant Linkage Principle.
Discussion Violations of the Topical Unity Principle and the Relevant Linkage Principle, for instance, because a popular site pointed to for irrelevant reasons, skew the results of the co-citation algorithm.
In this section we describe our algorithms for partitioning a given web page into pagelets and for detecting templates in a given collection of pages.
Before we describe our algorithm for partitioning a web page into pagelets, we would like to define what pagelets are. The following is a semantic definition of pagelets:
Definition 1 [Pagelet - semantic definition] A pagelet is a region of a web page that (1) has a single well-defined topic or functionality; and (2) is not nested within another region that has exactly the same topic or functionality.
That is, we have two contradicting requirements from a pagelet: (1) that it will be ``small'' enough as to have just one topic or functionality; and (2) that it will be ``big'' enough such that no other region that contains it also has the same topic (the nesting region may have a more general topic). Figure 1 demonstrates Definition 1 by the pagelet partitioning of the Yahoo! homepage.
In order to partition a page into pagelets, we need a syntactic definition of pagelets, which will materialize the intuitive requirements of the semantic definition into an actual algorithm. This problem was considered before by Chakrabarti [6] and Chakrabarti et al. [11]; they suggested a sophisticated algorithm to partition ``hubs'' in the context of the HITS/Clever algorithm into pagelets. Their algorithm, however, is intertwined with the application (Clever) and in particular it is context-dependent: the partitioning depends on the given query. Furthermore, the algorithm itself is non-trivial, and therefore it seems infeasible to run it on millions of pages at the data gathering phase.
Since our principal goal is to design efficient hypertext cleaning algorithms that run in data gathering time, we adopt a simple heuristic to syntactically define pagelets. This definition has the advantages of being context-free, admitting an efficient implementation, and approximating the semantic definition quite faithfully. Our heuristic uses the cues provided by HTML mark-up tags such as tables, paragraphs, headings, lists, etc.
The simplest approach to use HTML, and more generally XML, in page partitioning is to define the HTML elements (the ``tags'') as the pagelets. However, this approach suffers from several caveats: (1) the HTML structure is a tree and we would like a flattened partitioning of the page; and (2) the granularity of this partitioning is too fine, and does not meet the second requirement of Definition 1. We refine the approach in the following way:
Definition 2 [Pagelet - syntactic definition] An HTML element in the parse tree of a page p is a pagelet if (1) none of its children contains at least k hyperlinks; and (2) none of its ancestor elements is a pagelet.
The first requirement in Definition 2 corresponds to the first requirement of Definition 1. When an HTML element contains at least k links (k is a parameter of our choice; in our implementation we use k = 3), then it is likely to represent some independent idea/topic; otherwise, it is more likely to be topically integrated in its parent. The second requirement in Definition 2 achieves two goals: first, it implies a flattened partitioning of the page, and second, it ensures the second requirement of Definition 1. Definition 2 implies the page partitioning algorithm depicted in Figure 3.
Partition(p) {
Tp := HTML parse tree of p
Queue := root of Tp
while (Queue is not empty) {
v := top element in Queue
if (v has a child with at least k links)
push all the children of v to Queue
else
declare v as a pagelet
}
|
We now present two algorithms for detecting templates in a given collection of pages. Both algorithms are scalable and designed to process large amounts of pages efficiently. The first algorithm, called the local template detection algorithm, is more accurate for small sets of pages, while the second algorithm, called the global template detection algorithm, better suits large sets of pages.
Before we describe the algorithms, we define templates formally.
Definition 3 [Template - semantic definition] A template is a collection of pages that (1) share the same look and feel and (2) are controlled by a single authority.
Templates are usually created by a master HTML page that is shared by all the pages that belong to the site(s) of the authority that controls the template. The specific content of each page is inserted into ``place holders'' in this master HTML page. The outcome of this process is that all the templatized pages share common pagelets, such as navigational bars, ad banners, and logo images. The Yahoo! template, depicted in Figure 2, provides a good example of this notion.
The second requirement in Definition 3 is crucial in order to distinguish between templates and (a) whole-sale duplications of pages and (b) accidental similarities between independent pages.
In order to materialize the semantic definition of templates, we use the following syntactic definition. In the definition, we use the notation O(p) to denote the page owning a pagelet p, and C(p) to denote the content (HTML content) of the pagelet p.
Definition 4 [Template - syntactic definition] A template is a collection of pagelets p1,¼,pk that satisfies the following two requirements:
Definition 4 associates a template with the collection of pagelets that are shared by the templatized pages. The first requirement in Definition 4 ensures that the template pagelets are indeed part of the common ``look and feel'' of the templatized pages. The second requirement in Definition 4 ensures the second requirement of Definition 3. We use here the heuristic that templatized pages that are controlled by a single authority are usually reachable one from the other by an undirected path of other templatized pages (possibly through the root of the site). On the other hand, mirror sites and pages that share accidental similarities are not likely to link to each other.
In practice, we relax the first requirement of Definition 4, and require that pagelets in the same template are only ``approximately'' identical. That is, if every two pagelets in a collection p1,¼,pk are almost-identical and their owner pages form a connected component, we consider them to be a template. The reason for this relaxation is that in reality many templatized pages are slight perturbations of each other, due, e.g., to version inconsistencies. We use the shingling technique of Broder et al. [4] to determine almost-similarities. A shingle is a text fingerprint that is invariant under small perturbations. We associate with each template T a shingle s(T), and require each pagelet pÎ T to satisfy s(p) = s(T).
We further denote by O(T) the collection of pages owning the pagelets in T.
The algorithmic question our template detection algorithms are required to solve is as follows: given a collection of hyperlinked documents G = áVG,EG ñ drawn from a universe W = áVW, EW ñ (i.e., G is a sub-graph of W), enumerate all the templates T in W for which O(T) intersects VG. The algorithms assume the pages, links, and pagelets in G are stored as local database tables. We will show that their running time and space requirements are small—at most quasi-linear in the size of G.
The algorithms we present assume that G is stored as the following database relations:
Building these tables can be done by streaming through the pages in the dataset, and parsing their HTML text to extract their links and pagelets. Thus, it requires a constant time per page.
The first algorithm we consider is more suitable for document sets that consist only of a small fraction of the documents from the larger universe. In such sets it is very probable for a template T that only a small fraction of the pages in O(T) are contained in VG. This implies that, although O(T) forms an undirected connected component in W, O(T) ÇVG may not be connected in G. In this case, therefore, it makes more sense to validate only the first requirement of Definition 4. Note that for small sets of pages, we do not have to worry about accidental page similarities, because they are unlikely to occur. Whole-sale duplication of pages can be detected at a pre-processing step using the Broder et al. algorithm. The algorithm is described in Figure 4.
(1) Eliminate duplicate pages in G (2) Sort and group the pagelets in G according to their shingle. Each such group represents a template. (3) Enumerate the groups, and output the pagelets belonging to each group. |
To analyze the algorithm's complexity, we denote by N the number of pages in G, by M the number of links, and by K the number of pagelets in G. N,M, and K are the sizes of the tables PAGES, LINKS, and PAGELETS respectively.
The algorithm is very efficient: the first step can be carried out in O(N log N) time by computing the shingles of each pages, and sorting the pages according to the shingle value. Similarly, the second step requires O(K log K) steps, and the third step is just an O(K) linear scan of the pagelets. The space requirements (on top of the database tables) are logarithmic in K and N. Note that the operations performed in this algorithm (sorting and enumerating) are very standard in databases, and therefore are highly optimized in practice.
Our second algorithm, depicted in Figure 5, is more involved, and detects only templates that satisfy both requirements of Definition 4. This algorithm is well suited for large subsets of the universe, since in such subsets O(T) ÇVG is likely to be connected in G.
(1) Select all the pagelet shingles in PAGELETS that have at least two occurrences. Call the resulting table TEMPLATE_SHINGLES. These are the shingles of the re-occurring pagelets. (2) Extract from PAGELETS only the pagelets whose shingle occurs in TEMPLATE_SHINGLES. Call the resulting table TEMPLATE_CANDIDATES. These are all the pagelets that have multiple occurrences in G. (3) For every shingle s that occurs in TEMPLATE_SHINGLES define Gs to be the shingle's group: all the pages that contain pagelets whose shingle is s. By joining TEMPLATE_CANDIDATES and LINKS find for every s all the links between pages in Gs. Call the resulting relation TEMPLATE_LINKS. (4) Enumerate the shingles s in TEMPLATE_SHINGLES. For each one, load into main memory all the links between pages in Gs. (5) Use a BFS algorithm to find all the undirected connected components in Gs. Each such component is either a template or a singleton. Output the component if it is not a singleton. |
The algorithm works in two phases: in the first phase it extracts all the groups of syntactically similar pagelets (steps (1)-(2)) and in the second phase it partitions each such group into templates (steps (3)-(5)).
The main point here is that if T is a template that intersects VG, then s(T) will be one of the shingles in the relation TEMPLATE_SHINGLES. The group of the shingle s(T) should contain all the pagelets in T, but may contain pagelets from other pages, whose shingle happens to coincide with s(T). We extract the pagelets of T from the shingle's group using the connected components algorithm: the owners of the pagelets in T should form an undirected connected component.
This algorithm is also efficient: step (1) requires sorting PAGELETS, which takes O(K logK) steps and O(logK) space. Step (2) is just a linear scan of PAGELETS. Note that after this step the size of PAGELETS may decrease significantly, because we eliminate all the pagelets that occur only once in the dataset.
In step (3) we perform a triple join of TEMPLATE_CANDIDATES T1, TEMPLATE_CANDIDATES T2, and LINKS with constraints
In step (4) we assume that for every s, Gs is small enough to store in main memory. This is a reasonable assumption, since usually the size of a template is no more than a few thousands of pages. Thus even if Gs consists of several templates, we can store the few (tens) of thousands of records in main memory. This allows us to run a BFS algorithm on Gs, which would have been prohibitive if Gs was stored on disk. Thus, steps (4)-(5) take at most O(d2M) steps and logarithmic space.
All in all, the algorithm takes O(K logK + d2M) steps and O(d2M) space.
We now revisit the three case studies from the point of view of incorporating knowledge of pagelets and templates into them. We do this primarily to establish that the modifications required of the original algorithms are simple, minimal and natural.
Case 1: HITS and Clever Instead of using a graph consisting of all links (or all non-nepotistic links), we construct a graph over two sets of vertices. There is a vertex corresponding to each non-template pagelet in the base set, and another corresponding to each page in the base set. Edges are directed from vertices corresponding to pagelets to vertices corresponding to pages in the natural way, i.e., if and only if the pagelet contains a link to the page. Edges out of template pagelets are omitted entirely. The HITS/Clever algorithms can now be run as is. Hubs will always be pagelets, and authorities pages.
Case 2: Focused Crawling The focused crawler can use template and pagelet information in two ways.
Case 3: The co-citation algorithm The co-citation algorithm can exploit pagelet and template information in two ways.
In this section we demonstrate the benefit of template detection in improving precision of search engine results, by presenting experimental results of running the template/pagelet based implementation of Clever from Section 4.
In the experiments we compare six versions of Clever. Two of the versions use the classical ``page-based'' Clever, and the other four use the ``pagelet-based'' Clever of Section 4. The versions differ in the cleaning steps performed on the base set of pages/pagelets before starting to run the reinforcement hubs and authorities algorithm on this base set. We consider two cleaning steps: (1) FNM—filtering pages/pagelets that do not match the query term (i.e., the query term does not occur in their text), and (2) FT—filtering template-pagelets. FNM is applicable to both the page-based Clever and the pagelet-based Clever. FT is applicable only to pagelet-based Clever. Note the inherent difference between these two cleaning steps: FNM is query-dependent and can be performed only in query time, while FT is query-independent and can thus be carried out as a pre-processing step. The six Clever configurations are the following:
For detecting the template pagelets, we use the local template detection algorithm of Section 3.2, since the algorithm is given a fairly constrained collection of pages (the base set of pages).
Our main measure of concern for comparing these Clever versions is precision—the fraction of search results returned that are indeed directly relevant to the query. Since the main aim of template elimination is to clean the hypertext data from ``noise'', the measure of precision seems the most appropriate for testing the effectiveness of template elimination.
In order to determine relevance of search results to the query term, we had to employ human judgment. We scanned each of the results manually, and classified them as ``relevant'' or ``non-relevant''. A page was deemed relevant if it was a reasonable authority about the query term; pages that were indirectly related to the query term were classified as non-relevant.
We used the extended ARC suite of queries [10] to test the six Clever versions. The suite consists of the following 37 queries: ``affirmative action'', ``alcoholism'', ``amusement parks'', ``architecture'', ``bicycling'', ``blues'', ``cheese'', ``citrus groves'', ``classical guitar'', ``computer vision'', ``cruises'', ``Death Valley'', ``field hockey'' ``gardening'', ``graphic design'', ``Gulf war'', ``HIV'', ``Java'', ``Lipari'', ``lyme disease'', ``mutual funds'', ``National parks'', ``parallel architecture'', ``Penelope Fitzgerald'', ``recycling cans'', ``rock climbing'', ``San Francisco'', ``Shakespeare'', ``stamp collecting'', ``sushi'', ``table tennis'', ``telecommuting'', ``Thailand tourism'', ``vintage cars'', ``volcano'', ``zen buddhism'', and ``Zener''.
In the experiments we ran each of the six Clever versions on the ARC set of queries, and recorded the top 50 authorities found. We then manually tagged each of the results as ``relevant'' or ``non-relevant''. We determined for each run the ``precision@N'' for N = 10,20,30,40,50; that is, the fraction of the top N results that were tagged as ``relevant''.
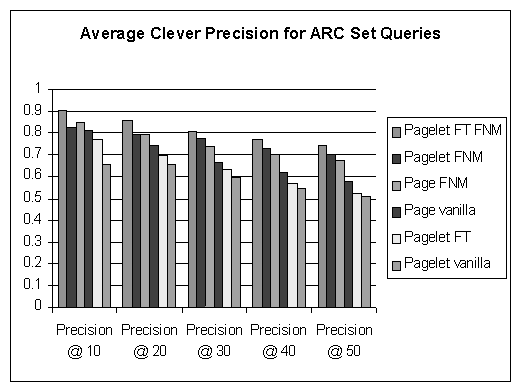
The chart in Figure 6 presents the average precision@N (N = 10,20,30,40,50) over the 37 ARC queries for each of the six Clever versions. The results clearly indicate that template elimination coupled with filtering non-matching pages/pagelets yields the most accurate results. For example, it improves the precision of page vanilla and page FNM at the top 10 from 81% and 85%, respectively, to 91%. The improvement at the top 50 is even more dramatic: from 58% and 67%, respectively, to 74%.
Reviewing the results manually reveals the reason for the improvements: page-based Clever, especially when running on broad topic queries for which there are many authoritative pages that reside within large commercial (and often templatized) web-sites, tends to drift towards the densely connected artificial communities created by templates (a phenomenon called in [21] the ``TKC Effect''). The filtering of non-matching pages does not always circumvent this problem, because sometimes the query term itself occurs in the template, and thus all the templatized pages contain the query too, whether or not they are indeed relevant to the query.
An anecdotal example of this phenomenon is illustrated by the results of Page FNM Clever on the query ``Java''. Table 1 lists those of the results that were classified as ``non-relevant''. Note that six out of the 18 non-relevant results belonged to the ``ITtoolbox'' domain. The ITtoolbox domain has many child sites that discuss various information technology tools; one of them is java.ittoolbox.com, which was indeed returned as result no. 22. However, each of the ITtoolbox sites (including the Java one) share a template, which contains a navigational bar with links to all the sister ITtoolbox sites. The high linkage between the ITtoolbox sites caused Clever to experience a TKC Effect. Note that the filtering of non-matching pages did not filter all the sister ITtoolbox sites from the base set, because all of them contain the term ``Java'' (in the template navigational bar). The Pagelet FT FNM Clever, on the other hand, detected the ITtoolbox template, eliminated it from the base set, and therefore returned only java.ittoolbox.com as one of the results. In total, Pagelet FT FNM Clever had a precision of 74% at the top 50 for the query ``Java'', compared to only 64% of Page FNM Clever.
| # | Title | URL |
| 27. | Sun Microsystems | www.sun.com |
| 29. | HTML Goodies Home Page | www.htmlgoodies.com |
| 30. | Linux Enterprise Ausgabe 11 2001 November | www.linuxenterprise.de/ |
| 31. | DevX Marketplace | marketplace.devx.com |
| 32. | Der Entwickler Ausgabe 6 2001 November Dezember | www.derentwickler.de/ |
| 33. | ITtoolbox Knowledge Management | knowledgemanagement.ittoolbox.com |
| 34. | EarthWeb com The IT Industry Portal | www.developer.com |
| 35. | entwickler com | www.entwickler.com |
| 36. | ITtoolbox EAI | eai.ittoolbox.com |
| 38. | www.xml-magazin.de/ | |
| 39. | DevX | www.devx.com |
| 41. | The Hot Meter | www.thehotmeter.com |
| 43. | HTML Clinic | www.htmlclinic.com |
| 45. | ITtoolbox Networking | networking.ittoolbox.com |
| 46. | FontFILE fonts... | www.fontfile.com |
| 47. | ITtoolbox Data Warehousing | datawarehouse.ittoolbox.com |
| 49. | ITtoolbox Portal for Oracle | oracle.ittoolbox.com |
| 50. | ITtoolbox Home | www.ittoolbox.com |
The chart of Figure 6 also indicates, however, that template elimination alone is not sufficient. In fact, the pagelet-based Clever with template elimination but without filtering of non-matching pagelets is doing worse than the classical page-based Clever. Pagelet-based Clever with no cleaning steps is doing the worst of all. These results are not surprising and they were noted before in [6]. Templates are just one source of noise in hyperlinked environments; frequently, many non-template pagelets in the base set are not relevant to the query. When such pagelets are not filtered from the base set, they magnify the ratio of noise to data significantly (because now each non-relevant page contributes many non-relevant pagelets to the base set), thereby causing the Clever algorithm to diverge. However, when most of the non-relevant pagelets are filtered from the base set, pagelet-based Clever is superior to page-based Clever, as demonstrated by the fact that the precision of the Pagelet FNM Clever (i.e., no template elimination) was better than that of Page FNM Clever.
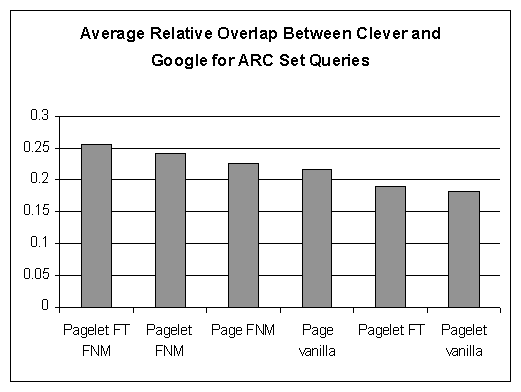
The chart in Figure 7 shows the average relative overlap of the Clever results with the top 50 results of Google [17], over the 37 ARC set queries. Here, we use Google as a benchmark, and seek at maximizing the overlap with its results. A large overlap indicates both high precision and high recall. The results presented in this chart are consistent with the precision results presented before: template elimination coupled with filtering non-matching pagelets yields the most accurate and qualitative results, but avoiding the filtering of non-matching pagelets is worse than using the page-based Clever.
Template Frequency In order to measure how common templates are, we checked what fraction of pages in the base set of each query contained template pagelets. The results presented in Table 2 demonstrate how common and fundamental this phenomenon has become. An interesting aspect of these results is that they give an indication for each given query how pervasive and commercialized its presence on the web is.
| Query | Fraction of Template Pages |
| affirmative action | 45% |
| alcoholism | 42% |
| amusement parks | 43% |
| architecture | 68% |
| bicycling | 49% |
| blues | 25% |
| cheese | 39% |
| citrus groves | 32% |
| classical guitar | 38% |
| computer vision | 32% |
| cruises | 46% |
| Death Valley | 51% |
| field hockey | 54% |
| gardening | 56% |
| graphic design | 28% |
| Gulf war | 40% |
| HIV | 43% |
| Java | 62% |
| Lipari | 53% |
| lyme disease | 32% |
| mutual funds | 67% |
| National parks | 33% |
| parallel architecture | 21% |
| Penelope Fitzgerald | 68% |
| recycling cans | 64% |
| rock climbing | 40% |
| San Francisco | 64% |
| Shakespeare | 39% |
| stamp collecting | 41% |
| sushi | 43% |
| table tennis | 44% |
| telecommuting | 39% |
| Thailand tourism | 37% |
| vintage cars | 22% |
| volcano | 48% |
| zen buddhism | 44% |
| Zener | 13% |
| Average | 43% |
In this paper we discussed the problem of detecting templates in large hypertext corpora, such as the web. We identified three basic principles, the Hypertext IR Principles, that underly most hypertext information retrieval and data mining systems, and argued that templates violate all three of them. We showed experimentally that templates are a pervasive phenomenon on the web, thus posing a significant obstacle to IR and DM systems. We proposed a new approach for dealing with violations of the Hypertext IR Principles, in which the hypertext cleaning steps required to eliminate these violations are delegated from the data analysis systems, where they were handled traditionally, to the data gathering systems. We presented two algorithms for detecting templates: an algorithm that fits small document sets and an algorithm that fits large document sets. Both algorithms are highly efficient in terms of time and space, and thus can be run by a data gathering system on large collections of hypertext documents stored locally. We demonstrated the benefit of template elimination, by showing experimentally that it improves the precision of the search engine Clever at all levels of recall.
There are a number of open questions to be addressed in future work:
We would like to thank Inbal Bar-Yossef for her invaluable assistance with running the experiments and evaluating their results. We thank Ravi Kumar and the anonymous referees for useful comments.